
※2024年8月13日更新
生成AIがますます日常生活やビジネスシーンで利用されるようになっています。それに伴いサービスの普及も急速に進んでおり、今の生成AIはどうなっているんだ?もうChatGPTは古い?といった状況になっている方もいらっしゃると思います。
そこで、今回は下記の生成AIの有料プランについて特徴や性能を比較していきます。
- OpenAIのChatGPT 4o
- GoogleのGemini 1.5 Pro
- AnthropicのClaude 3.5 Sonnet
その他にも、Llama、Grok、Copilot、Stable diffusion、など様々な生成AIが登場していますが、今回はその中でもチャットサービスに特化していて注目度の高い3つをピックアップしました。ぜひ参考にしてみてください。
各チャットAIサービスの特徴は?
Claude 3.5 sonnet – テキスト生成に特化したチャットAI
Anthropic社の最新AI「Claude 3.5 sonnet」はテキスト生成に特化したAIとなっています。中でも日本語入出力に定評があるため文章作成に向いているのと、Artifactsというプレビュー機能により資料作成やプログラミングに向いているのが特徴です。
メリット
- 多くのベンチマークテストで競合よりもスコアが高い性能
- 日本語の入出力精度に定評がある
- Artifactsによるプレビュー機能でプログラミングや資料作成に使いやすい
デメリット
- 画像生成ができない(画像認識は可能)
- 音声出力ができない
- 動画解析ができない
ChatGPT 4o – 万能型の高性能チャットAI
OpenAI社が提供するChatGPT 4oは動画以外のマルチモーダルに対応し、あらゆるベンチマークテストで高水準なスコアを出していることが特徴です。
また、GPT Storeという他のユーザーが作成したカスタムGPTを利用できることも利点で、自分でカスタマイズしなくともプロンプト指示を効率化できます。
メリット
- 多くのベンチマークテストで高水準のスコア
- 画像生成ができる
- 音声入出力に対応、会話ができる
- データ分析の精度に定評がある
- GPT Storeで他のユーザーが作成したカスタムGPTを利用できる
デメリット
- 動画解析ができない
Gemini 1.5 Pro – 大量のデータ処理に優れたチャットAI
Google社が提供するGeminiはマルチモーダルに対応し、大量のデータ処理ができるのが特徴です。Youtubeを提供していることもあり動画解析ができるのはGeminiのみです。(2024年8月時点)
また、短期記憶に優れており何十枚もあるPDFや大量のデータ処理にはGeminiが向いています。これはコンテキストトークンが約200万と競合に比べて圧倒的に多いことが理由です。(GPT -4o:約13万トークン、Claude3.5:約20万トークン)
メリット
- 大量のデータ処理が可能(コンテキストトークンが200万)
- 動画解析ができる
- 画像生成ができる
- 音声入出力ができる
デメリット
- ベンチマークテストのスコアが他AIにやや劣る
- 特定タスクへのカスタマイズが不可
*Geminiは2024年8月1日に最新モデル「Gemini 1.5 Pro Exp 0801」がGoogle AI Studioで使えるようになりました。Claude3.5やGPT-4oよりもChatbot Arenaでスコアを上回ったそうです。
料金比較
次に、各AIの料金プランを比較してみましょう。
| Claude 3.5 Sonnet | ChatGPT 4o | Gemini 1.5 Pro | |
|---|---|---|---|
| 個人プラン(月額) | 20ドル/名 | 20ドル/名 | 2900円/名 |
| チームプラン(月額) | 30ドル/名 (年払い25ドル) | 30ドル/名 (年払い25ドル) | – |
| 無料オプション | 10回/5時間まで無料 | 10回/5時間まで無料 | 初回1ヶ月無料 |
チームプランは複数人の登録から使えるプランで、セキュリティの強化や使用量の増加などのメリットがあります。
基本機能比較
各AIの基本的な機能を見てみましょう。以下の表に、主要な機能の比較をまとめました。
| Claude 3.5 Sonnet | ChatGPT 4o | Gemini 1.5 Pro | |
|---|---|---|---|
| テキスト生成 | ◎ | ◎ | ◯ |
| 画像生成 | ✗ | ◯ | ◯ |
| 音声出力 | ✗ | ◯ | ◯ |
| 動画解析 | ✗ | ◯ | ◯ |
| コーディングサポート | ◎ | ◯ | ◯ |
| 大規模データ処理 | ◯ | ◯ | ◎ |
| カスタマイズ性 | ◯(ClaudeProjects) | ◯(GPTs) | ✗* |
*GeminiはGemsというカスタマイズ機能が近日搭載されることを発表しています。参考
各AIの性能評価を比較
各AIの性能評価を行うために、企業は「ベンチマークテスト」と呼ばれるテストを用いてスコアを公開しています。ベンチマークテストとは、AIモデルが特定のタスクに対してどれだけ効果的に対応できるかを評価するための指標です。こちらを使用して性能を比較していきましょう。
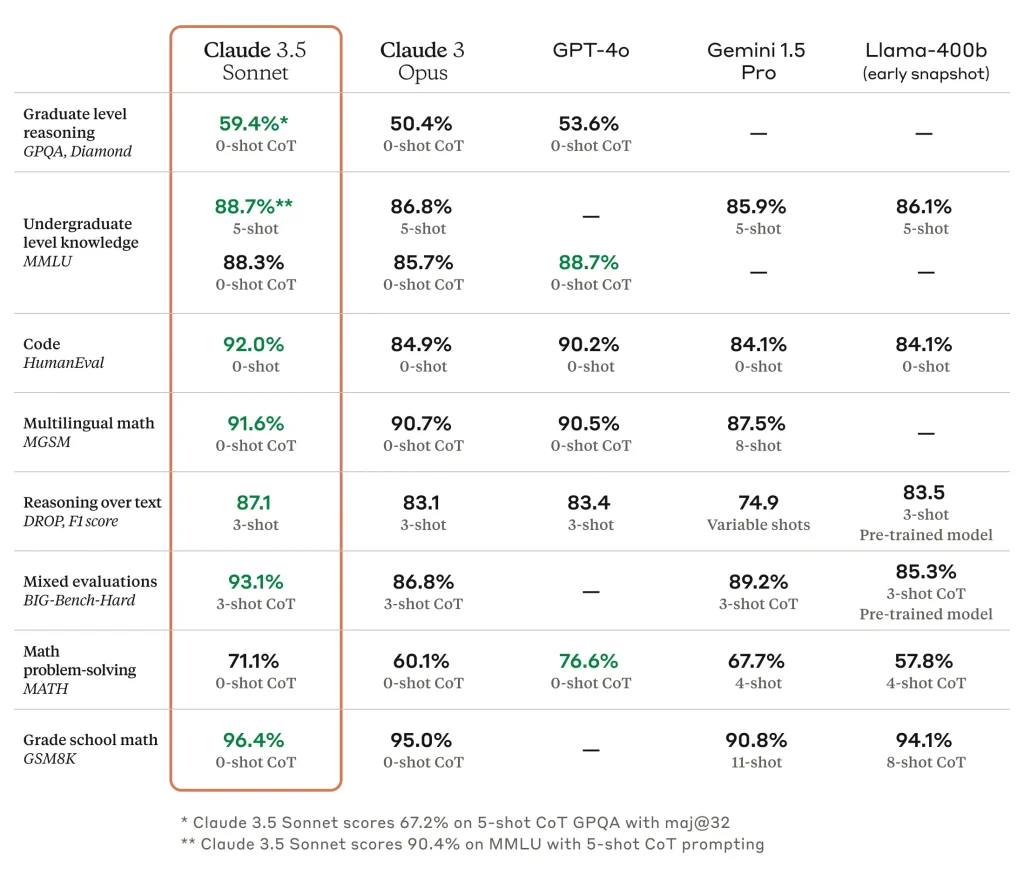
テキスト処理性能の比較
AIのテキスト処理性能について、文章生成、プログラム生成、数学的推論などの能力を比較します。全体的にClaude3.5のスコアが高いことが分かり、ChatGPT 4oも高水準のスコアをだしており、正確な知識量や数学に関しては負けていない事がわかります。
要約した表グラフ
| Claude 3.5 Sonnet | ChatGPT 4o | Gemini 1.5 Pro | |
|---|---|---|---|
| 複雑な推論 | 59.4% | 53.9% | – |
| 正確な知識量 | 88.7% (5-shot*) | 88.7% (0-shot Cot*) | 85.9% (5-shot*) |
| 文脈の理解 | 87.1 | 83.4 | 74.9 |
| プログラム生成 | 92.0% | 90.2% | 84.1% |
| 大学レベルの数学 | 71.1% | 76.6% | 67.7% |
*5-shot:5つの例題を与えた上でタスクを解かせる方法。
*0-shot Cot:事前に例題を与えずにタスクを解かせる方法。
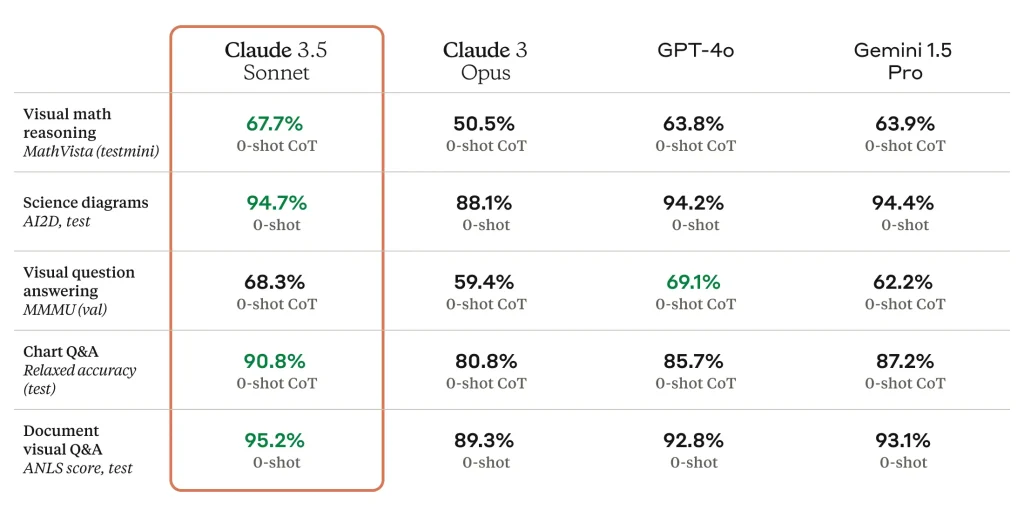
視覚データ処理能力の評価
AIの視覚データ処理能力について、画像や文書内の視覚情報に基づく質問応答能力を比較します。プロンプトで画像ファイルを使用することも増えているかと思いますが、それを正確に認識しているかが分かります。こちらもClaude 3.5のスコアが高いことが分かります。
要約した表グラフ
| Claude 3.5 Sonnet | ChatGPT 4o | Gemini 1.5 Pro | |
|---|---|---|---|
| 文書理解 | 95.2% | 92.8% | 93.1% |
| 数学能力 | 67.7% | 63.8% | 63.9% |
| 正確な知識量 | 68.3% | 69.1% | 62.2% |
| 図表理解 | 90.8% | 85.7% | 87.2% |
ベンチマークテストの内容一覧
比較されていたベンチマークテストの内容をまとめました。詳しく見たい方は参考にしてみてください。
GPQA
AIモデルの一般的な質問応答能力を評価するテストで、数値が高いと多岐にわたるトピックに対する正確性と一貫性が高いことを示します。
MMLU
AIモデルの幅広いタスクに対する理解力を評価するテストで、数値が高いと様々な分野で専門的な知識と推論能力が高いことを示します。
HumanEval
AIモデルのプログラム生成能力を評価するテストで、数値が高いと特定のタスクや関数を実行するためのコードを正確に生成できることを示します。
MGSM
AIモデルの小学校レベルの数学問題に対する理解と解答能力を評価するテストで、数値が高いと基礎的な算数問題に正確に解答できることを示します。
DROP
AIモデルの段落にわたる離散的な推論能力を評価するテストで、数値が高いと段落内の情報を基に具体的な質問に正確に解答できることを示します。
Big-Bench Hard
AIモデルの高度な推論と理解の能力を評価するテストで、数値が高いと複雑で挑戦的なタスクに対して効果的に対応できることを示します。
MATH
AIモデルの数学的推論能力を評価するテストで、数値が高いと基本的な計算から高度な数学的推論まで幅広い数学問題に正確に解答できることを示します。
GSM8K
AIモデルの小学校レベルの数学問題に対する理解と解答能力を評価するテストで、数値が高いと基礎的な算数問題に正確に解答できることを示します。このテストは、AIモデルが多ステップの数学的推論をどれだけ正確に行えるかを測定します。
MathVista
AIモデルの数学的推論と視覚理解を評価するテストで、数値が高いと視覚的な数式や問題を正確に解釈し解答できることを示します。
AI2D
AIモデルの文章理解能力を評価するテストで、数値が高いと文章内の視覚情報を正確に読み取り、解釈できることを示します。
MMMU
AIモデルの複数の学問分野にわたるマルチモーダル(テキストと視覚情報を含む)理解力と推論力を評価するテストで、数値が高いと多様な学問分野において高度な知識と推論能力を持っていると言えます。
ChartQA
AIモデルのチャートやグラフに基づく質問応答能力を評価するテストで、数値が高いとチャートやグラフの情報を正確に理解し、質問に答えることができることを示します。
Document visual Q&A
AIモデルの文書内の視覚情報に基づく質問応答能力を評価するテストで、数値が高いと文書内の視覚情報を正確に理解し、質問に答えることができることを示します。
AI2D
AIモデルが文書内の視覚情報に基づいて質問に正確に答える能力を評価するためのテストで、数値が高いとモデルが視覚情報を正確に理解し、その情報を基に質問に適切に答える能力が優れていることを示します。
執筆にあたり参考にさせていただいた記事・動画一覧
- Gemini(ジェミニ)とは?料金・使い方・活用事例、アプリ最新情報を紹介
- Geminiの性能評価に使われているベンチマークの概要まとめ
- ChatGPTやClaude超えと噂のGemini 1.5 Pro Exp 0801を試してみた
- Claude3.5の使い方~「ChatGPTでいいでしょ」と思ってるビジネスパーソンのためのClaude入門&ChatGPTとの違いや使い分けシーン
- Claudeは画像を生成できますか?
- 最強のAIチャットボットを決めようとしている「Chatbot Arena」をみんなに触ってほしい(ユーザー登録不要)
ダブルノットの“ChatGPT初級編セミナー”のご案内
「AIと対話しながら、仕事の進め方を変える」その第一歩を、一緒に体験してみませんか?
ダブルノットの“ChatGPT初級編セミナー”は、生成AIをこれから会社に導入したい・使ってみたい経営者の方や、自分自身で少し使ってみたけれど活用しきれていないという方向けの入門プログラムです。
大切なのは“AIに任せる”ことではなく、“AIとともに考える”ことです。
セミナーでは、生成AIの基本的な知識と使い方をわかりやすく解説し、実際の業務でどのように活用できるのかを10時間で学んでいただけます。
まるで運転教習所に入る感覚で、この講座を通じて、生成AIという新しい相棒との付き合い方を身につけてみませんか?

